Our work focuses broadly on asking questions about organismal function and evolution using genomic data. The huge amount of data currently being produced allows us to ask and answer questions on a genomic scale that have never been possible before. Our questions largely revolve around the relative roles of natural selection and genetic drift in shaping nucleotide, gene family, and gene expression variation both within and between species. Although most of the empirical work has been on systems such as humans, flies, mosquitoes, and tomatoes, members of the lab can work on topics and organisms that appeal to them. This page covers several major topics currently being studied.
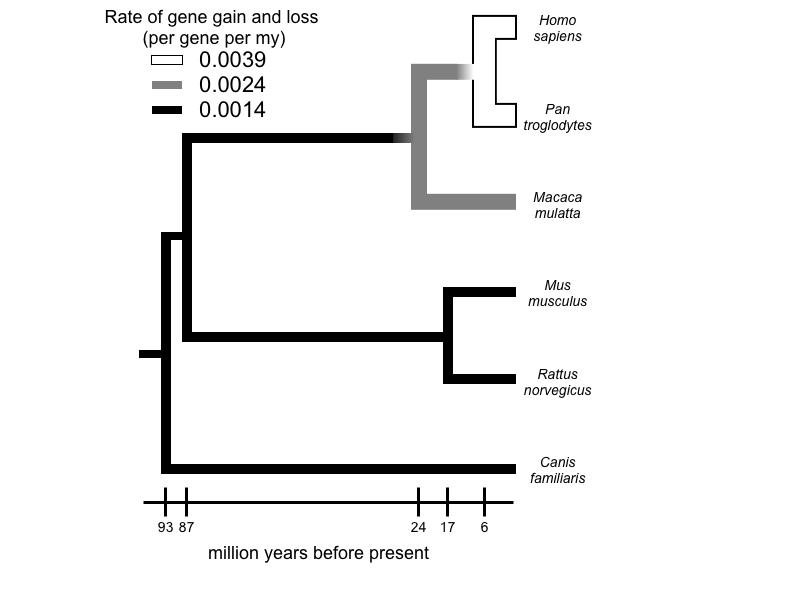
The evolution of gene gain and loss
Comparison of whole genomes has revealed large and frequent changes in the size of gene families, the result of gene duplication and loss. Comparative genomic analyses allow us to identify large-scale patterns of change and to make inferences regarding the role of natural selection in gene gain and loss. To make these analyses possible, we have developed multiple models and methods for inferring gene gain and loss. These methods include a stochastic birth-and-death model for gene family evolution, applied in the software package, CAFE, and multiple reconciliation methods for use with gene trees (implemented in the software packages GRAMPA and reconcILS). Application of this method to data from multiple whole genomes of many groups is revealing remarkable patterns of gene gain and loss.
Population genomics
Selective, demographic, and random processes all determine the frequency of alleles in a population and differences between species. One of the major goals of population genetics has been to uncover which of these processes is acting in natural populations through a combination of directed empirical studies and theoretical models that provide expectations under a variety of conditions. While classical work in the field involved single loci or limited multiple locus studies and models, the availability of genomic-scale data requires genomic-scale approaches. We have pursued these questions in a wide variety of systems, using a wide variety of computational and statistical approaches. The work has resulted in new methods for distinguishing demography from selection, distinguishing different forms of positive selection, and more recently, using and analyzing machine learning approaches to population genetic inference.
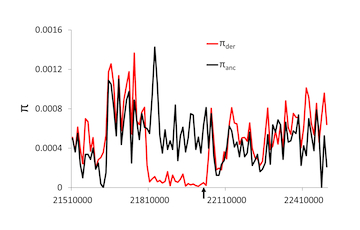
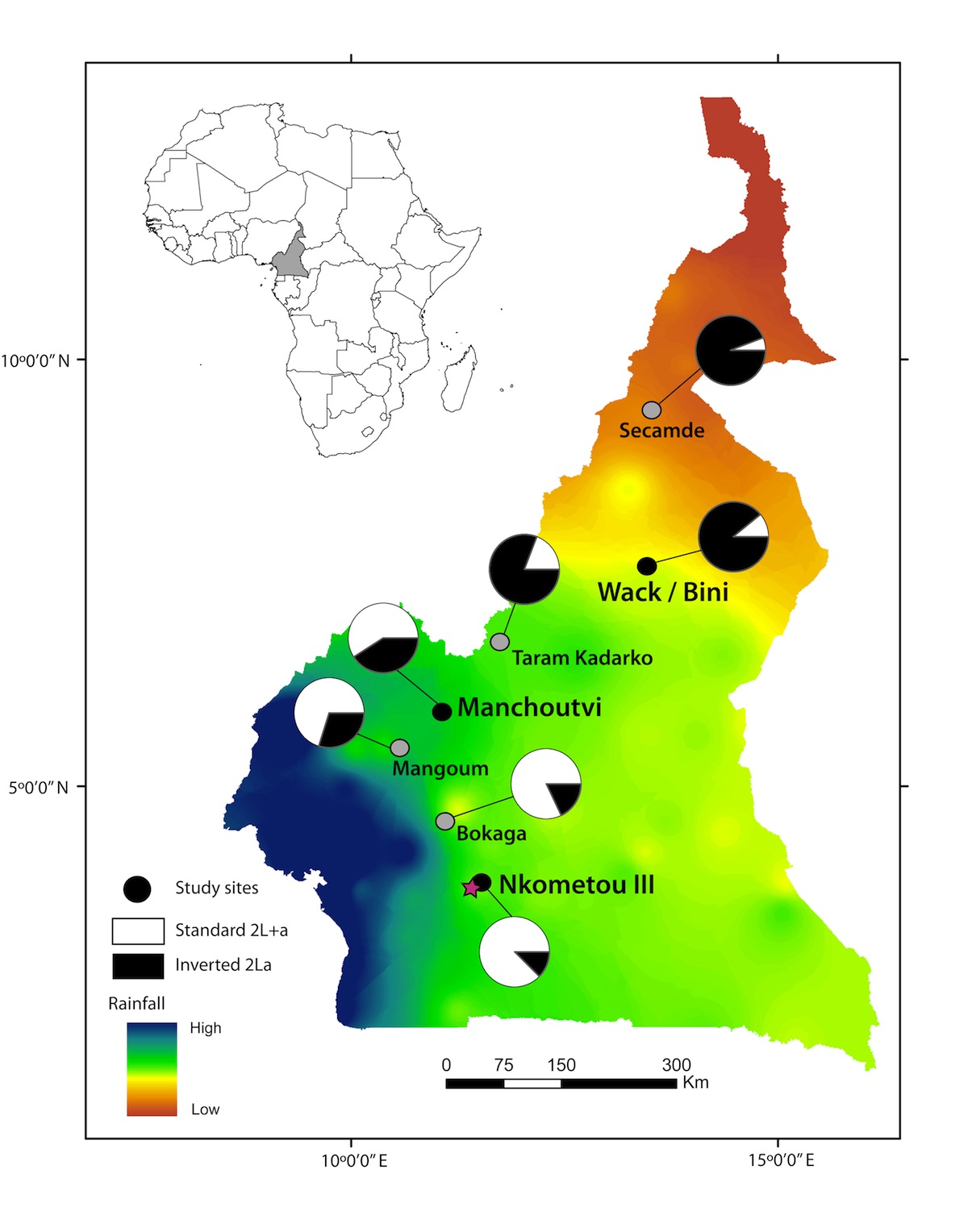
Speciation genomics
Population genomic data are being applied in new and creative ways to recently diverged lineages. One of the goals of the field of speciation genomics is to understand how the patterns of divergence uncovered by such studies are related to mechanisms of reproductive isolation. We have been particularly interested in the roles of introgression and selection in shaping heterogeneous patterns of divergence between closely related species. This work has built on much of our more general research into population genomics, but also encompasses the development of many new approaches for detecting introgression.
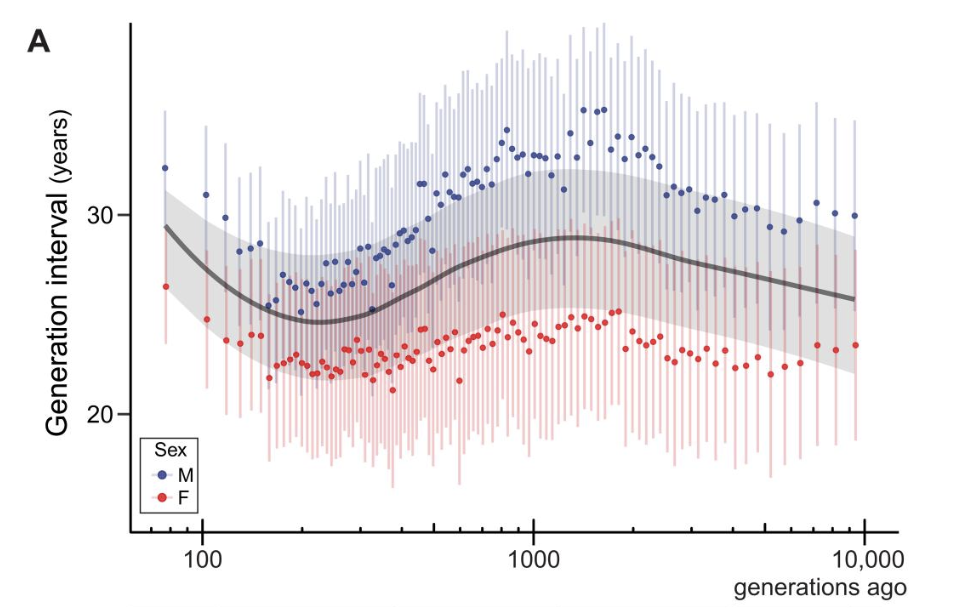
The evolution of mutation rates
Parents leave many mutations to their offspring, but this number differs among species and between the sexes. Using pedigree-based studies of mutation rates across mammals, our work has focused on explaining the evolution of this complex trait. We have found that variation in the mutation rate among species is largely driven by generation time: longer-lived organisms pass on more mutations. Our newer work on differences between the sexes attempts to determine the developmental and molecular mechanisms underlying male-mutation bias.